Tuesday, June 28, 2011
Saturday, June 25, 2011
Math Forum - Ask Dr. Math
Math Forum - Ask Dr. Math
inf means "infimum," or "greatest lower bound." This is slightly different from minimum in that the greatest lower bound is defined as: x is the infimum of the set S [in symbols, x = inf (S)] iff: a) x is less than or equal to all elements of S b) there is no other number larger than x which is less than or equal to all elements of S. Basically, (a) means that x is a lower bound of S, and (b) means that x is greater than all other lower bounds of S.
Friday, June 24, 2011
Thursday, June 23, 2011
Data mining Blog, Preprocessing, Normalization
Data mining Blog, Preprocessing, Normalization
Outliers can be found by using a technique called box plot (http://en.wikipedia.org/wiki/Box_plot)
Before we normalize the data set, we need to check for outliers
There are two possible ways to handle outliers in the data
1. Ignore them, remove from the data set (or)
2. Reassign the value to of appropriate upper or lower threshold.
Before we normalize the data set, we need to check for outliers
There are two possible ways to handle outliers in the data
1. Ignore them, remove from the data set (or)
2. Reassign the value to of appropriate upper or lower threshold.
Thursday, June 16, 2011
Thursday, June 9, 2011
Thursday, June 2, 2011
Monday, May 9, 2011
Friday, May 6, 2011
Monday, May 2, 2011
Stat 375 – Inference in Graphical Models
Stat 375
Stat 375 – Inference in Graphical Models
Andrea Montanari, Stanford University, Winter 2011
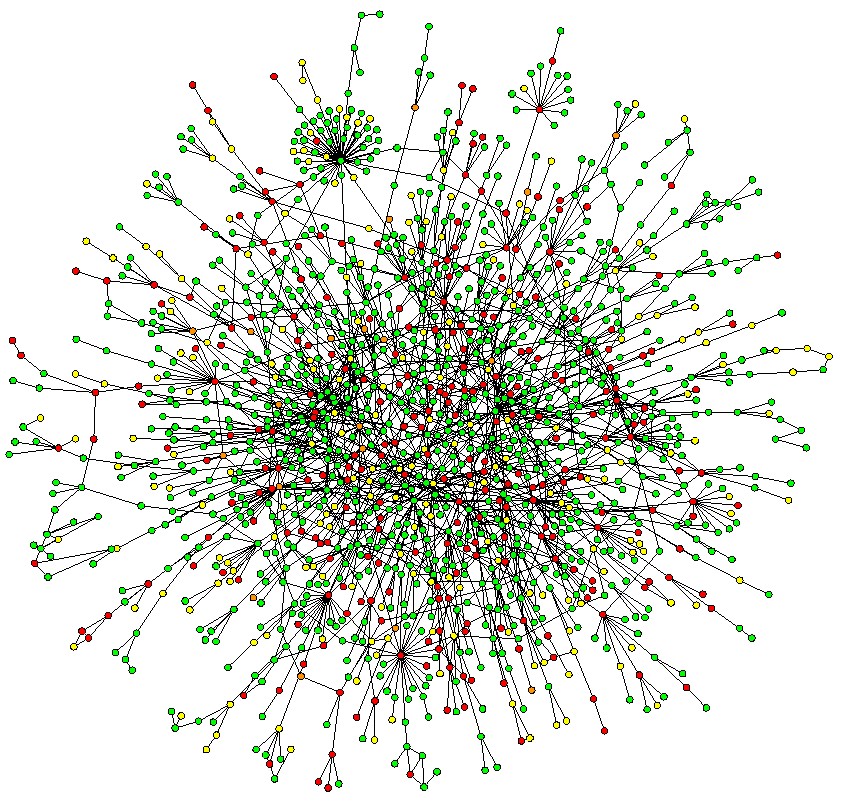 | Graphical models are a unifying framework for describing the statistical relationships between large collections of random variables. Given a graphical model, the most fundamental (and yet highly non-trivial) task is compute the marginal distribution of one or a few such variables. This task is usually referred to as ‘inference’. The focus of this course is on sparse graphical structures, low-complexity inference algorithms, and their analysis. In particular we will treat the following methods: variational inference; message passing algorithms; belief propagation; generalized belief propagation; survey propagation; learning. Applications/examples will include: Gaussian models with sparse inverse covariance; hidden Markov models (Viterbi and BCJR algorithms, Kalman filter); computer vision (segmentation, tracking, etc); constraint satisfaction problems; machine learning (clustering, classification); communications. |
Sunday, May 1, 2011
Thursday, April 28, 2011
Wednesday, April 27, 2011
Classifier Showdown « Synaptic
Classifier Showdown « Synaptic
take a closer look at three different classifiers and discuss three different types of classifiers: naive bayesian classifiers, support vector machines and modular multilayer perceptron neural networks.
Saturday, April 23, 2011
Subscribe to:
Posts (Atom)