Thursday, March 31, 2011
Machine Learning, etc: Graphical Models class notes
Machine Learning, etc: Graphical Models class notes
- Jeff Bilmes' Graphical Models course , gives detailed introduction on Lauritzen's results, proof of Hammersley-Clifford results (look in "old scribes" section for notes)
- Kevin Murphy's Graphical Models course , good description of I-maps
- Sam Roweis' Graphical Models course , good introduction on exponential families
- Stephen Wainwright's Graphical Models class, exponential families, variational derivation of inference
- Michael Jordan's Graphical Models course, his book seems to be the most popular for this type of class
- Lauritzen's Graphical Models and Inference class , also his Statistical Inference class , useful facts on exponential families, information on log-linear models, decomposability
- Donna Precup's class , some stuff on structure learning
Wednesday, March 30, 2011
Dumbo
Home - GitHub
Dumbo is a project that allows you to easily write and run Hadoop programs in Python (it’s named after Disney’s flying circus elephant, since thelogo of Hadoop is an elephant and Python was named after the BBC series “Monty Python’s Flying Circus”). More generally, Dumbo can be considered to be a convenient Python API for writing MapReduce programs.
Documentation
Sunday, March 27, 2011
clustering - Which machine learning library to use - Stack Overflow
clustering - Which machine learning library to use - Stack Overflow
clustering - Which machine learning library to use - Stack Overflow
http://stackoverflow.com/questions/2915341/which-machine-learning-library-to-use
Some Notes of SVM from S-O-F
This is a very good illustration of how SVM-works:
Links from
The original is from math.stackexchange.com
The first answer:
As mokus explained, practical support vector machines use a non-linear kernel function to map data into a feature space where they are linearly separable:

Lots of different functions are used for various kinds of data. Note that an extra dimension is added by the transformation.
(Illustration from Chris Thornton, U. Sussex.)
The 2nd answer: YouTube video that illustrates an example of linearly inseparable points that become separable by a plane when mapped to a higher dimension
"Non-linear classification", with a link tohttp://en.wikipedia.org/wiki/Kernel_trick which explains the technique more generally.
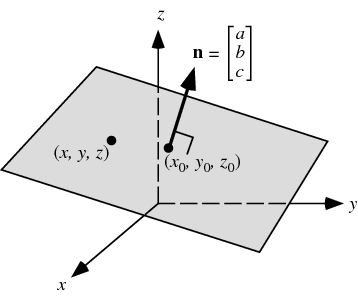
And for SVM, a very good explanation for the equation- hyperplane is: the w*x + b = 0
language agnostic - Support vector machines - separating hyperplane question - Stack Overflow
It is the equation of a (hyper)plane using a point and normal vector.
Think of the plane as the set of points P such that the vector passing from P0 to P is perpendicular to the normal
Check out these pages for explanation:
http://mathworld.wolfram.com/Plane.html
http://en.wikipedia.org/wiki/Plane_%28geometry%29#Definition_with_a_point_and_a_normal_vector
--
♥ ¸¸.•*¨*•♫♪♪♫•*¨*•.¸¸♥
libsvm compute distance to hyperplane python
Some collections that relate to how to compute the distance to hyperplane in LibSVM in Python
https://github.com/bwallace/curious_snake
From Gábor Melis' () blog
Active Learning for cl-libsvm
Some-other-source:
http://agbs.kyb.tuebingen.mpg.de/km/bb/showthread.php?tid=1022
| |||
RE: Distance to hyperplane (/computing w) from Python?(24-11-2008 05:27 PM)wallace Wrote: One question though; I've noticed the si->obj value will at times be negative, and so therefore |w|^2 is as well. This seems rather odd to me. Am I perhaps doing something wrong? Thanks again. si->obj is 0.5 alpha^T Q alpha - sum alpha_i = -(primal obj) = -(w^Tw/2 + C \sum \xu_i) <= 0 what you should use is that alpha^TQalpha = w^Tw in Solve of svm.cpp, we have g = (Qalpha - e) available. By calculaing alpha^T (g+e) you get w^Tw Hope this helps. |

{kind=link}
Saturday, March 26, 2011
What are the best blogs about data? - Quora
What are the best blogs about data? - Quora
Below is a snapshot:
* OkTrends http://blog.okcupid.com/
* SNA Projects Blog (LinkedIn) http://sna-projects.com/blog/
* Data Evolution (Dataspora) http://dataspora.com
* FiveThirtyEight http://www.fivethirtyeight.com/
* Brendan O'Connor's Blog http://anyall.org
* Alex Smola http://blog.smola.org
* Undirected Grad (Jurgen Van Gael) http://undirectedgrad.blogspot.com/
* Pete Warden http://petewarden.typepad.com
* Jeffry Heer http://hci.stanford.edu/jheer/
* Measuring Measures (Bradford Cross) http://measuringmeasures.com
* Info Vegan (Clay Johnson) http://www.infovegan.com
* High scalability http://highscalability.com
* hilary mason http://www.hilarymason.com
* Sunlight Labs http://sunlightlabs.com
* Datawrangling http://www.datawrangling.com
* Flowing Data http://flowingdata.com
* Geeking With Greg http://glinden.blogspot.com
* Business|bytes|genes|molecules http://mndoci.com
* Data Mining: Text Mining, Visualization, and Social Mediahttp://datamining.typepad.com
* Machine Learning (Theory) http://hunch.net
* Code - Open Blog - NYTimes http://open.blogs.nytimes.com
* LingPipe Blog http://lingpipe-blog.com/
* Peter Norvig http://norvig.com/
* Infochimps http://blog.infochimps.org
* Joseph Turian http://metaoptimize.com/blog/
* Aaron koblin http://www.aaronkoblin.com/work....
* igvita.com http://www.igvita.com
* SimpleGeo blog http://blog.simplegeo.com/
* Chris Diehl http://www.cpdiehl.org/blog.html
* Juice Analytics http://www.juiceanalytics.com
* Dolores Labs Blog http://blog.doloreslabs.com
* UMBC eBiquity Blog http://ebiquity.umbc.edu/blogger/
* Random Etc. (Tom Carden) http://www.tom-carden.co.uk
* Michael G. Noll's Blog http://www.michael-noll.com
* John D. Cook http://www.johndcook.com/blog/
* Daniel Lemire http://www.daniel-lemire.com/blog/
* Cerebral Mastication (J.D. Long) http://www.cerebralmastication.com/
* Eager Eyes http://eagereyes.org/
* Ben Lorica (O'Reilly Radar) http://radar.oreilly.com/ben/
* Marginally Interesting (Mikio L. Braun) http://blog.mikiobraun.de/
* Neoformix http://www.neoformix.com/
* Zero Intelligence Agents (Drew Conway) http://www.drewconway.com/zia/
* Bitquill http://www.bitquill.net
* Michael Nielsen http://michaelnielsen.org/blog/
* Ben Fry http://benfry.com/writing/
* Machine Learning Etc (Yaroslav Bulatov) http://yaroslavvb.blogspot.com
* Chris Harrison http://www.chrisharrison.net
* Guardian Data Blog (Simon Rogers): http://www.guardian.co.uk/news/d...
* Surprise & Coincidence (Ted Dunning) http://tdunning.blogspot.com
* Simple Complexity http://simplecomplexity.net
* Semantic Void (anand kishore) http://www.semanticvoid.com/blog/
* matpalm http://matpalm.com/
* Paco Nathan http://ceteri.blogspot.com/
* Lee Byron http://leebyron.com
* manAmplified (Chris K Wensel) http://www.manamplified.org
* Dumbotics http://dumbotics.com
* Road To Failure (Bradford Stephens) http://www.roadtofailure.com/
* Bio and Geo Informatics http://hackmap.blogspot.com/
* kiwitobes http://blog.kiwitobes.com/
* Yet Another Machine Learning Blog http://yamlb.wordpress.com/
* Cloudera Blog http://www.cloudera.com/blog/
* Inductio Ex Machina (Mark Reid) http://mark.reid.name/iem/
* Statistical Modeling, Causal Inference, and Social Sciencehttp://www.stat.columbia.edu/~ge...
* atbrox http://atbrox.com
* Bitwiese http://www.bitwiese.de/
* SquareCog http://squarecog.wordpress.com/
* Chris Riccomini http://www.riccomini.name/
* Sematext Blog http://blog.sematext.com/
* Data Miner's Blog http://blog.data-miners.com/
* Saaien tist (Jan Aerts) http://saaientist.blogspot.com/
* Byte Mining (@datajunkie) http://www.bytemining.com/
* Ka-Ping Yee http://zesty.ca/
* Jeffrey Veen http://www.veen.com/jeff/index.html
* SNA Projects Blog (LinkedIn) http://sna-projects.com/b
* Data Evolution (Dataspora) http://dataspora.com
* FiveThirtyEight http://www.fivethirtyeigh
* Brendan O'Connor's Blog http://anyall.org
* Alex Smola http://blog.smola.org
* Undirected Grad (Jurgen Van Gael) http://undirectedgrad.blo
* Pete Warden http://petewarden.typepad
* Jeffry Heer http://hci.stanford.edu/j
* Measuring Measures (Bradford Cross) http://measuringmeasures.
* Info Vegan (Clay Johnson) http://www.infovegan.com
* High scalability http://highscalability.co
* hilary mason http://www.hilarymason.co
* Sunlight Labs http://sunlightlabs.com
* Datawrangling http://www.datawrangling.
* Flowing Data http://flowingdata.com
* Geeking With Greg http://glinden.blogspot.c
* Business|bytes|genes|mole
* Data Mining: Text Mining, Visualization, and Social Mediahttp://datamining.typepad
* Machine Learning (Theory) http://hunch.net
* Code - Open Blog - NYTimes http://open.blogs.nytimes
* LingPipe Blog http://lingpipe-blog.com/
* Peter Norvig http://norvig.com/
* Infochimps http://blog.infochimps.or
* Joseph Turian http://metaoptimize.com/b
* Aaron koblin http://www.aaronkoblin.co
* igvita.com http://www.igvita.com
* SimpleGeo blog http://blog.simplegeo.com
* Chris Diehl http://www.cpdiehl.org/bl
* Juice Analytics http://www.juiceanalytics
* Dolores Labs Blog http://blog.doloreslabs.c
* UMBC eBiquity Blog http://ebiquity.umbc.edu/
* Random Etc. (Tom Carden) http://www.tom-carden.co.
* Michael G. Noll's Blog http://www.michael-noll.c
* John D. Cook http://www.johndcook.com/
* Daniel Lemire http://www.daniel-lemire.
* Cerebral Mastication (J.D. Long) http://www.cerebralmastic
* Eager Eyes http://eagereyes.org/
* Ben Lorica (O'Reilly Radar) http://radar.oreilly.com/
* Marginally Interesting (Mikio L. Braun) http://blog.mikiobraun.de
* Neoformix http://www.neoformix.com/
* Zero Intelligence Agents (Drew Conway) http://www.drewconway.com
* Bitquill http://www.bitquill.net
* Michael Nielsen http://michaelnielsen.org
* Ben Fry http://benfry.com/writing
* Machine Learning Etc (Yaroslav Bulatov) http://yaroslavvb.blogspo
* Chris Harrison http://www.chrisharrison.
* Guardian Data Blog (Simon Rogers): http://www.guardian.co.uk
* Surprise & Coincidence (Ted Dunning) http://tdunning.blogspot.
* Simple Complexity http://simplecomplexity.n
* Semantic Void (anand kishore) http://www.semanticvoid.c
* matpalm http://matpalm.com/
* Paco Nathan http://ceteri.blogspot.co
* Lee Byron http://leebyron.com
* manAmplified (Chris K Wensel) http://www.manamplified.o
* Dumbotics http://dumbotics.com
* Road To Failure (Bradford Stephens) http://www.roadtofailure.
* Bio and Geo Informatics http://hackmap.blogspot.c
* kiwitobes http://blog.kiwitobes.com
* Yet Another Machine Learning Blog http://yamlb.wordpress.co
* Cloudera Blog http://www.cloudera.com/b
* Inductio Ex Machina (Mark Reid) http://mark.reid.name/iem
* Statistical Modeling, Causal Inference, and Social Sciencehttp://www.stat.columbia.
* atbrox http://atbrox.com
* Bitwiese http://www.bitwiese.de/
* SquareCog http://squarecog.wordpres
* Chris Riccomini http://www.riccomini.name
* Sematext Blog http://blog.sematext.com/
* Data Miner's Blog http://blog.data-miners.c
* Saaien tist (Jan Aerts) http://saaientist.blogspo
* Byte Mining (@datajunkie) http://www.bytemining.com
* Ka-Ping Yee http://zesty.ca/
* Jeffrey Veen http://www.veen.com/jeff/
Subscribe to:
Posts (Atom)