Monday, February 28, 2011
Rashid Bin Muhammad's Home Page
Rashid Bin Muhammad's Home Page
 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
ICML 2011 Structured Sparsity: Learning and Inference Workshop
ICML 2011 Structured Sparsity: Learning and Inference Workshop
Improvements in engineering and data acquisition techniques have rendered high dimensional data easily available. As a result, statistical analysis of high-dimensional data has become frequent in many scientific fields ranging from biology, genomics and health sciences to astronomy, economics and machine learning. Despite the high dimensionality and complexity of the data, many problems have structure that makes efficient statistical inference possible. Examples of such structure include sparsity, sparse conditional independence graphs, low-dimensional manifolds, low-rank factorization, latent variables and semiparametric copulas. In the last decade, sparsity inducing regularization methods have proven to be very useful in high-dimensional models both for selection of a small set of highly predictive variables and for uncovering of physical phenomena underlying many systems under scientific investigation. Nowadays, sparsity is a major tool for handling statistical problems in high dimensions.
A lot of effort in the machine learning and statistics community has been invested in understanding theoretical properties of the l1-regularization procedures and devising efficient algorithms for large scale problems. As a result, we have a good understanding of the theory behind the l1-regularization methods and are capable of fitting simple models to large amounts of data, for example, linear regression and Gaussian models. Unfortunately, the theoretical results based on these oversimplified models often do not reflect difficulties encountered in the real life problems. For example, it is hard (and often impossible) to check whether the model assumptions hold for any given data set. Furthermore, practitioners have access to a lot of prior knowledge about the problem which should be incorporated into the model. On the other hand, many Bayesian procedures work well in practice and provide a flexible framework to incorporate prior knowledge. However, little or nothing can be said mathematically about their generalization performance.
Going beyond simple sparsity, there have been a lot of extensions of the Lasso, such as, group Lasso, fused Lasso, multi-task Lasso, elastic-net, etc. These extensions aim at incorporating additional structure into the model and try to improve the Lasso in cases when it fails. The structure may be pre-given or hidden in the data. Learning and exploiting such structure is a crucial first step towards better exploring and understanding complex datasets. This raises two key questions:
How can we automatically learn the hidden structure from the data?
Once the structure is learned or pre-given, how can we utilize the structure to conduct more effective inference?
Machine learning and statistics communities have addressed these two key questions from different perspectives: Bayesian vs. frequentist, parametric vs. nonparametric, optimization vs. integration.
Below we provide some applications that benefit from exploiting of complex structure:
a) Sparse conditional independence graphs: Sparse network models are typically learned by maximizing a l1-penalized likelihood or pseudo-likelihood. These approaches, while computationally efficient, ignore prior information that is known about the system under consideration. For example, one biological application involves estimating regulatory networks of genes, about which there is a lot of information collected through experiments.
b) Multi-task learning: The premise of multi-task learning is that by learning several related tasks the efficiency of an estimation procedure can be improved. Commonly it is assumed that all tasks share the same underlying structure, such as sparsity or low rank representation. In practice, this is not necessarily the case and the main question is how to incorporate additional knowledge about the relationship between tasks into an estimation procedure.
c) Model-based compressed sensing: Under the sparsity assumption, the compressed sensing theory guarantees that a signal can be recovered with certain number of measurements. Given additional structure about the unknown signal, beyond sparsity, the number of measurements needed to recover the signal can be dramatically reduced without sacrificing robustness.
The aim of the workshop is to bring together theory and practice in modeling and exploring structure in high-dimensional data. We would like to invite researchers working on methodology, theory and applications, both from the frequentist and Bayesian point of view, to participate in the workshop. We encourage genuine interaction between proponents of different approaches and hope to better understand possibilities for modeling of structure in high dimensional data
collection of Tutorials and videos on Data minin
the collection of Tutorials and videos on Data mining.
Tutorials: http://www.dataminingtools.net/browsetutorials.php
Videos: http://www.dataminingtools.net/browse.php
Tutorials: http://www.dataminingtools.net/browsetutorials.php
Videos: http://www.dataminingtools.net/browse.php
Hype about conditional probability puzzles - Statistical Modeling, Causal Inference, and Social Science
Hype about conditional probability puzzles - Statistical Modeling, Causal Inference, and Social Science
Hype about conditional probability puzzles
Jason Kottke posts this puzzle from Gary Foshee that reportedly impressed people at a puzzle-designers' convention:
I have two children. One is a boy born on a Tuesday. What is the probability I have two boys?The first thing you think is "What has Tuesday got to do with it?" Well, it has everything to do with it.
Sunday, February 27, 2011
AI on the Web
AI on the Web
From :http://aima.cs.berkeley.edu/ai.html
AI on the Web
This page links to 820 pages around the web with information on Artificial Intelligence. Links in Bold* followed by a star are especially useful and interesting sites. Links with a + sign at the end have "tooltip" information that will pop up if you put your mouse over the link for a second or two.
list of AI books.
Saturday, February 26, 2011
Notebooks - Cosma
Notebooks By Cosma
There is a list of frequently asked questions (FAQ), along with answers, and a colophon, which explains more than anyone would want to know about how these pages are put together. If your question isn't answered in either place, feel free to write, though, sadly, I can't promise a timely reply.
---Cosma
Burned all my notebooks
What good are notebooks
If they won't help me survive?
But a curiosity of my type remains after all the most agreeable of all vices --- sorry, I meant to say: the love of truth has its reward in heaven and even on earth. ---Nietzsche, Beyond Good and Evil, 45They're, well, notebooks --- things I find amusing, outrageous, strange or otherwise noteworthy; notes towards works-in-glacial-progress; hemi-demi-semi-rants; things I want to learn more about; lists of references; quotations from the Talking Heads where appropriate. If you can help with any of these, I'd be grateful; if you can tell me of anything I can profitably prune, I'd be even more grateful.
There is a list of frequently asked questions (FAQ), along with answers, and a colophon, which explains more than anyone would want to know about how these pages are put together. If your question isn't answered in either place, feel free to write, though, sadly, I can't promise a timely reply.
---Cosma
Graph Theory Lessons
Graph Theory Lessons
By Dr. Christopher P. Mawata
- Lesson 1: Null graphs
- Lesson 2: Handshaking Lemma
- Lesson 3: Isomorphism
- Lesson 4: Complete Graphs, Subgraphs
- Lesson 5: Regular Graphs
- Lesson 6: Platonic Graphs
- Lesson 7: Adjacency Matrices
- Lesson 8: Graph Coloring
- Lesson 9: Bipartite Graphs
- Lesson 10: Stars and Tripartite Graphs
- Lesson 11: Circuits and Wheels
- Lesson 12: Euler Circuits, Hamilton Circuits and Directed Graphs
- Lesson 13: Trees and Searches
- Lesson 14: Unions and Sums
- Lesson 15: Complements
- Lesson 16: Prisms
- Lesson 17: Laces
- Lesson 18: Line Graphs
- Lesson 19: Grids
- Lesson 20: Spanning Trees
- Lesson 21: Planar Graphs
- Lesson 22: Dual Graphs
- Lesson 23: Weighted Graphs, Shortest Paths, and Minimal Spanning Trees
- More Lessons at http://www.mathcove.net/petersen/
Machine Learning 大家
From HERE.
Machine Learning 大家(1):M. I. Jordan
在我的眼里,M Jordan无疑是武林中的泰山北斗。他师出MIT,现在在berkeley坐镇一方,在附近的两所名校(加stanford)中都可以说无出其右者,stanford的Daphne Koller虽然也声名遐迩,但是和Jordan比还是有一段距离。
Jordan身兼stat和cs两个系的教授,从他身上可以看出Stat和ML的融合。
Jordan 最先专注于mixtures of experts,并迅速奠定了自己的地位,我们哈尔滨工业大学的校友徐雷跟他做博后期间,也在这个方向上沾光不少。Jordan和他的弟子在很多方面作出了开创性的成果,如spectral clustering, Graphical model和nonparametric Bayesian。现在后两者在ML领域是非常炙手可热的两个方向,可以说很大程度上是Jordan的lab一手推动的。
更难能可贵的是, Jordan不仅自己武艺高强,并且揽钱有法,教育有方,手下门徒众多且很多人成了大器,隐然成为江湖大帮派。他的弟子中有10多人任教授,个人认
为他现在的弟子中最出色的是stanford的Andrew Ng,不过由于资历原因,现在还是assistant professor,不过成为大教授指日可待;另外Tommi Jaakkola和David Blei也非常厉害,其中Tommi Jaakkola在mit任教而David Blei在cmu做博后,数次获得NIPS最佳论文奖,把SVM的最大间隔方法和Markov network的structure结构结合起来,赫赫有名。还有一个博后是来自于toronto的Yee Whye Teh,非常不错,有幸跟他打过几次交道,人非常nice。另外还有一个博后居然在做生物信息方面的东西,看来jordan在这方面也捞了钱。这方面他有一个中国学生Eric P. Xing(清华大学校友),现在在cmu做assistant professor。
总的说来,我觉得 Jordan现在做的主要还是graphical model和Bayesian learning,他去年写了一本关于graphical model的书,今年由mit press出版,应该是这个领域里程碑式的著作。3月份曾经有人答应给我一本打印本看看,因为Jordan不让他传播电子版,但后来好像没放在心上(可见美国人也不是很守信的),人不熟我也不好意思问着要,可以说是一大遗憾. 另外发现一个有趣的现象就是Jordan对hierarchical情有独钟,相当多的文章都是关于hierarchical的,所以能 hierarchical大家赶快hierarchical,否则就让他给抢了。
用我朋友话说看jordan牛不牛,看他主页下面的Past students and postdocs就知道了。
Machine Learning大家(2):D. Koller
D. Koller是1999年美国青年科学家总统奖(PECASE)得主,IJCAI 2001 Computers and Thought Award(IJCAI计算机与思维奖,这是国际人工智能界35岁以下青年学者的最高奖)得主,2004 World Technology Award得主。
最先知道D koller是因为她得了一个大奖,2001年IJCAI计算机与思维奖。Koller因她在概率推理的理论和实践、机器学习、计算博弈论等领域的重要贡献,成为继Terry Winograd、David Marr、Tom Mitchell、Rodney Brooks等人之后的第18位获奖者。说起这个奖挺有意思的,IJCAI终身成就奖(IJCAI Award for Research Excellence),是国际人工智能界的最高荣誉; IJCAI计算机与思维奖是国际人工智能界35岁以下青年学者的最高荣誉。早期AI研究将推理置于至高无上的地位; 但是1991年牛人Rodney Brooks对推理全面否定,指出机器只能独立学习而得到了IJCAI计算机与思维奖; 但是koller却因提出了Probabilistic Relational Models 而证明机器可以推理论知而又得到了这个奖,可见世事无绝对,科学有轮回。
D koller的Probabilistic Relational Models在nips和icml等各种牛会上活跃了相当长的一段时间,并且至少在实验室里证明了它在信息搜索上的价值,这也导致了她的很多学生进入了 google。虽然进入google可能没有在牛校当faculty名声响亮,但要知道google的很多员工现在可都是百万富翁,在全美大肆买房买车的主。
Koller的研究主要都集中在probabilistic graphical model,如Bayesian网络,但这玩意我没有接触过,我只看过几篇他们的markov network的文章,但看了也就看了,一点想法都没有,这滩水有点深,不是我这种非科班出身的能趟的,并且感觉难以应用到我现在这个领域中。
Koller 才从教10年,所以学生还没有涌现出太多的牛人,这也是她不能跟Jordan比拟的地方,并且由于在stanford的关系,很多学生直接去硅谷赚大钱去了,而没有在学术界开江湖大帮派的影响,但在stanford这可能太难以办到,因为金钱的诱惑实在太大了。不过Koller的一个学生我非常崇拜,叫 Ben Taskar,就是我在(1)中所提到的Jordan的博后,是好几个牛会的最佳论文奖,他把SVM的最大间隔方法和Markov network结合起来,可以说是对structure data处理的一种标准工具,也把最大间隔方法带入了一个新的热潮,近几年很多牛会都有这样的workshop。 我最开始上Ben Taskar的在stanford的个人网页时,正赶上他刚毕业,他的顶上有这么一句话:流言变成了现实,我终于毕业了!可见Koller是很变态的,把自己的学生关得这么郁闷,这恐怕也是大多数女faculty的通病吧,并且估计还非常的push!
Machine learning 大家(3):J. D. Lafferty
大家都知道NIPS和ICML向来都是由大大小小的山头所割据,而John Lafferty无疑是里面相当高的一座高山,这一点可从他的publication list里的NIPS和ICML数目得到明证。虽然江湖传说计算机重镇CMU现在在走向衰落,但这无碍Lafferty拥有越来越大的影响力,翻开AI兵器谱排名第一的journal of machine learning research的很多文章,我们都能发现author或者editor中赫然有Lafferty的名字。
Lafferty给人留下的最大的印象似乎是他2001年的conditional random fields,这篇文章后来被疯狂引用,广泛地应用在语言和图像处理,并随之出现了很多的变体,如Kumar的discriminative random fields等。虽然大家都知道discriminative learning好,但很久没有找到好的discriminative方法去处理这些具有丰富的contextual inxxxxation的数据,直到Lafferty的出现。
而现在Lafferty做的东西好像很杂,semi-supervised learning, kernel learning,graphical models甚至manifold learning都有涉及,可能就是像武侠里一样只要学会了九阳神功,那么其它的武功就可以一窥而知其精髓了。这里面我最喜欢的是semi- supervised learning,因为随着要处理的数据越来越多,进行全部label过于困难,而完全unsupervised的方法又让人不太放心,在这种情况下 semi-supervised learning就成了最好的。这没有一个比较清晰的认识,不过这也给了江湖后辈成名的可乘之机。到现在为止,我觉得cmu的semi- supervised是做得最好的,以前是KAMAL NIGAM做了开创性的工作,而现在Lafferty和他的弟子作出了很多总结和创新。
Lafferty 的弟子好像不是很多,并且好像都不是很有名。不过今年毕业了一个中国人,Xiaojin Zhu(上海交通大学校友),就是做semi-supervised的那个人,现在在wisconsin-madison做assistant professor。他做了迄今为止最全面的Semi-supervised learning literature survey,大家可以从他的个人主页中找到。这人看着很憨厚,估计是很好的陶瓷对象。另外我在(1)中所说的Jordan的牛弟子D Blei今年也投奔Lafferty做博后,就足见Lafferty的牛了。
Lafferty做NLP是很好的,著名的Link Grammar Parser还有很多别的应用。其中language model在IR中应用,这方面他的另一个中国学生ChengXiang Zhai(南京大学校友,2004年美国青年科学家总统奖(PECASE)得主),现在在uiuc做assistant professor。
Machine learning 大家(4):Peter L. Bartlett
鄙人浅薄之见,Jordan比起同在berkeley的Peter Bartlett还是要差一个层次。Bartlett主要的成就都是在learning theory方面,也就是ML最本质的东西。他的几篇开创性理论分析的论文,当然还有他的书Neural Network Learning: Theoretical Foundations。
UC Berkeley的统计系在强手如林的北美高校中一直是top3,这就足以证明其肯定是群星荟萃,而其中,Peter L. Bartlett是相当亮的一颗星。关于他的研究,我想可以从他的一本书里得到答案:Neural Network Learning: Theoretical Foundations。也就是说,他主要做的是Theoretical Foundations。基础理论虽然没有一些直接可面向应用的算法那样引人注目,但对科学的发展实际上起着更大的作用。试想vapnik要不是在VC维的理论上辛苦了这么多年,怎么可能有SVM的问世。不过阳春白雪固是高雅,但大多数人只能听懂下里巴人,所以Bartlett的文章大多只能在做理论的那个圈子里产生影响,而不能为大多数人所广泛引用。
Bartlett在最近两年做了大量的Large margin classifiers方面的工作,如其convergence rate和generalization bound等。并且很多是与jordan合作,足见两人的工作有很多相通之处。不过我发现Bartlett的大多数文章都是自己为第一作者,估计是在教育上存在问题吧,没带出特别牛的学生出来。
Bartlett的个人主页的talk里有很多值得一看的slides,如Large Margin Classifiers: Convexity and Classification;Large Margin Methods for Structured Classification: Exponentiated Gradient Algorithms。大家有兴趣的话可以去下来看看。
Machine learning 大家(5): Michael Collins
Michael Collins (http://people.csail.mit.edu/mcollins/)
自然语言处理(NLP)江湖的第一高人。出身Upenn,靠一身叫做Collins Parser的武功在江湖上展露头脚。当然除了资质好之外,其出身也帮了不少忙。早年一个叫做Mitchell P. Marcus的师傅传授了他一本葵花宝典-Penn Treebank。从此,Collins整日沉迷于此,终于练成盖世神功。
学成之后,Collins告别师傅开始闯荡江湖,投入了一个叫AT&T Labs Research的帮会,并有幸结识了Robert Schapire、Yoram Singer等众多高手。大家不要小瞧这个叫AT&T Labs Research的帮会,如果谁没有听过它的大名总该知道它的同父异母的兄弟Bell Labs吧。
言归正传,话说Collins在这里度过了3年快乐的时光。其间也奠定了其NLP江湖老大的地位。并且练就了Discriminative Reranking, Convolution Kernels,Discriminative Training Methods for Hidden Markov Models等多种绝技。然而,世事难料,怎奈由于帮会经营不善,这帮大牛又不会为帮会拼杀,终于被一脚踢开,大家如鸟兽散了。Schapire去了 Princeton, Singer 也回老家以色列了。Collins来到了MIT,成为了武林第一大帮的六袋长老,并教授一门叫做的Machine Learning Approaches for NLP(http://www.ai.mit.edu/courses/6.891-nlp/) 的功夫。虽然这一地位与其功力极不相符,但是这并没有打消Collins的积极性,通过其刻苦打拼,终于得到了一个叫Sloan Research Fellow的头衔,并于今年7月,光荣的升任7袋Associate Professor。
在其下山短短7年时间内,Collins共获得了4次世界级武道大会冠军(EMNLP2002, 2004, UAI2004, 2005)。相信年轻的他,总有一天会一统丐帮,甚至整个江湖。
看过Collins和别人合作的一篇文章,用conditional random fields 做object recogntion。还这么年轻,admire to death!
Machine learning 大家(6): Dan Roth
Dan Roth (http://l2r.cs.uiuc.edu/~danr/)
统计NLP领域的众多学者后,我得出了一个惊人的结论,就是叫Daniel的牛人特别多: 大到MT领域成名已久的Prof. Dan Melamed,小到Stanford刚刚毕业的Dan Klein,
中间又有Dan jurafsky这种牛魔王,甚至Michael Collins的师弟Dan Bikel (IBM Research),ISI的Dan Marcu,获得过无数次TREC QA评比冠军的Prof. Dan Moldovan (UTexas Dallas),UC Berkeley毕业的Dan Gildea (U Rochester)。但是,在众多的Dan中,我最崇拜的还是UIUC的Associate Professor,其Cognitive Computation Group的头头Dan Roth。
这位老兄也是极其年轻的,Harvard博士毕业整十年,带领其团队撑起了UIUC Machine Learning以及NLP领域的一片灿烂天空。其领导开发的SNoW工具可谓是一把绝世好剑,基本达到了”又想马儿跑,又想马儿不吃草”的境界,在不损失分类精度的条件下,学习和预测速度空前。什么?你不知道SNoW?它和白雪公主有什么关系?看来我也得学学”超女”的粉丝们,来一个扫盲了: SNoW是Sparse Network of Winnows的简称,其中实现了Winnow算法,但是记住Sparse Network才是其重点,正是因为有了这块玄铁,SNoW之剑才会如此锋利。
近年来Roth也赶时髦,把触角伸向了Structured Data学习领域,但与其他人在学习的时候就试图加入结构化信息(典型的如CRF)不同,Roth主张在预测的最后阶段加入约束进行推理,这可以使的学习效率极大的提高,同时在某些应用上,还取得了更好的结果。还有就是什么Kernel学习,估计他也是学生太多,安排不下了,所以只好开疆扩土。
Harvard出身的Roth,理论功底也极其深厚,好多涉及统计学习理论的工作就不是我这种学工科的人关心的了。
个人补充一点:南京大学的一个Machine Learning的牛人网名也叫Daniel
附: 个人也很喜欢 John Langford
Key Scientific Challenges Program | Yahoo! Labs
Yahoo Labs post this year <Key Scientific Challenges Program.>
The challenges listed below and submit an application between January 24th - March 11th, 2011 to be considered for the Key Scientific Challenges Program.
Key Scientific Challenges







Friday, February 25, 2011
Notes on Suffix tree
# From wiki <http://en.wikipedia.org/wiki/Suffix_tree>
# A good explanation : <http://marknelson.us/1996/08/01/suffix-trees/>
# A very nice tutorial on Suffix tree <http://www.cise.ufl.edu/~sahni/dsaaj/enrich/c16/suffix.htm>
[Applications]
> longest repeated substring problem:
The longest repeated substring problem is finding the longest substring of a string that occurs at least twice. This problem can be solved in linear time and space by building a suffix tree for the string, and finding the deepest internal node in the tree. The string spelled by the edges from the root to such a node is a longest repeated substring. The problem of finding the longest substring with at least k occurrences can be found by first preprocessing the tree to count the number of leaf descendants for each internal node, and then finding the deepest node with at least k descendants.Solutions from Sartaj Sahni
Find the longest substring ofSthat appears at leastm > 1times. This query can be answered inO(|S|)time in the following way:
(a) Traverse the suffix tree labeling the branch nodes with the sum of the label lengths from the root and also with the number of information nodes in the subtrie.
(b) Traverse the suffix tree visiting branch nodes with information node count>= m. Determine the visited branch node with longest label length.
Note that step (a) needs to be done only once. Following this, we can do step (b) for as many values of
m as is desired. Also, note that when m = 2 we can avoid determining the number of information nodes in subtries. In a compressed trie, every subtrie rooted at a branch node has at least two information nodes in it.[Some Notes]
An example of Surfix Tree:
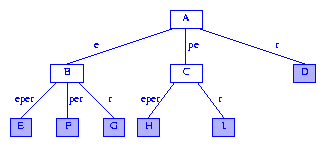
Figure 4 A more humane drawing of a suffix tree
A fundamental observation used when searching for a pattern
P in a string S is that P appears in S (i.e., P is a substring of S) iff P is a prefix of some suffix of S. Let's take the above figure as an example,
if follow A->C->H : pe is the prefix of eper
[Some Related Codes]
- Suffix Trees by Dr. Sartaj Sahni (CISE Department Chair at University of Florida)
- Suffix Trees by Lloyd Allison
- NIST's Dictionary of Algorithms and Data Structures: Suffix Tree
- suffix_tree ANSI C implementation of a Suffix Tree
- libstree, a generic suffix tree library written in C
- Tree::Suffix, a Perl binding to libstree
- Strmat a faster generic suffix tree library written in C (uses arrays instead of linked lists)
- SuffixTree a Python binding to Strmat
♥ ¸¸.•*¨*•♫♪♪♫•*¨*•.¸¸♥
Thursday, February 24, 2011
Active Learning Group discussion on AL for NLP
From the Active Learning Group about AL for NLP(23.02.2011):
Below are part of the email:
[Problem]
- A project to explore the suitability of active learning for a number of specialized annotation tasks
- difficult to reliably reproduce some fairly "common results" in the literature.
- the problem is specifically on sequence tagging tasks such as NER using common datasets such as CoNLL-2003 and MUC6.
- The "common results" means learning curves (f-measure vs tokens of training data) where the active learning selection strategy outperforms a random strategy at all points along the curve.
[Responses]
- using DL-Learner and OWL.
- used Active Learning over pos tags to learn passive in the Tiger Corpus Navigator:
- There is also a web demo: http://hanne.aksw.org
- The method was not compared to approaches *not* using active learning, because the algorithm only works feasible with few examples.
--
♥ ¸¸.•*¨*•♫♪♪♫•*¨*•.¸¸♥
LibreOffice 3.3.1
The newest Libreffice: Up to Feb 23, 2011
LibreOffice 3.3.1 Has Been Released!
http://download.documentfoundation.org/libreoffice/stable/3.3.1/
http://download.documentfoundation.org/libreoffice/stable/3.3.1/
Related Linkes
downoload: http://www.libreoffice.org/download
&
installation: http://www.libreoffice.org/get-help/installation/
&
installation: http://www.libreoffice.org/get-help/installation/
Installation of LibreOffice on Debian/Ubuntu-based Linux systems
The instructions here are for installing LibreOffice in US English, on a 32-bit system; there will be slight differences in some directory names if you are installing LibreOffice on a 64-bit system, but the process is basically the same and – hopefully – you will not find these instructions difficult to follow.
For instructions on how to install a language pack (after having installed the US English version of LibreOffice), please read the “Installing a Language Pack” section.
1) After downloading the installer archive file, use Nautilus to decompress it in a directory of your choice (your
Desktop directory, for example). After decompressing it, you will see that the contents have been unpacked into a directory calledLibO_3.3.0rc1_Linux_x86_install-deb_en-US. Open a Nautilus file manager window, and change directory to that directory.2) The directory contains a subdirectory called
DEBS. Change directory to the DEBS directory.3) Right-click within the
DEBS directory and choose “Open in Terminal”. A terminal window will open. From the command line of the terminal window, enter the following command (you will be prompted to enter your root user's password before the command will execute):sudo dpkg -i *.deb4) The above dpkg command does the first part of the installation process. To complete the process, you also need to install the desktop integration packages. To do this, change directory to the
desktop-integration directory that is within the DEBS directory, using the following command:cd desktop-integrationNow run the dpkg command again:
sudo dpkg -i *.debThe installation process is now completed, and you should have icons for all the LibreOffice applications in your desktop's Applications/Office menu.
♥ ¸¸.•*¨*•♫♪♪♫•*¨*•.¸¸♥
Wednesday, February 23, 2011
Machine Learning Summer School Main/Home Page
Machine Learning Summer School Main/Home Page
The use of observations to automatically improve the capabilities of programs has been a long standing challenge since the invention of the computer. Machine learning strives to achieve this goal using techniques from diverse areas such as computer science, engineering, mathematics, and statistics.
Rapid progress in machine learning has made it the method of choice for many applications in areas such as business intelligence, computational biology, computational finance, computer vision, information retrieval, natural language processing and other areas of science and engineering. The summer school aims to bring both the theory and practice of machine learning to research students, researchers as well as professionals who wish to understand and apply machine learning.
Participants will get the opportunity to interact with leading experts in the field and potentially form collaborations with other participants. It is suitable for those who wish to learn about the area as well as those who wish to broaden their expertise. For research students, the summer school provides an intensive period of study, appropriate for those doing research in machine learning or related application areas. For academics and researchers, the summer school provides an opportunity to learn about new techniques and network with others with similar interests. For professionals who use machine learning, this is an opportunity to learn the state of the art techniques from leading experts in the area.
The summer school is part of the machine learning summer school series started in 2002. It is co-organized by Institute for Infocomm Research, National Infocomm Australia (NICTA), National University of Singapore (NUS), and Pattern Analysis, Statistical Modelling and Computational Learning (PASCAL2)with generous support from the Air Force Office of Scientific Research, Asian Office of Aerospace Research and Development
Python Online Source
Some Python Online Sources:
Differences between Python 2 and 3 - This articles explains the subtle and not so subtle differences (print ('...'), input(...) and eval(input(..)) instead of raw_input and input in 3, etc)
Python Style Guide - Readability Counts! And hey this document shows a desire for standardization of coding to aid everyone in the community
PyDev - IDE
Generators Generators in Python:
Tricks, Tips, and Hacks:
Python Tips, Tricks, and Hacks
MIT OpenCourseWare
MIT 6.00 Intro to Computer Science & Program
Under MIT OpenCourseWare, all the lectures are available on MIT youtube channel with handouts and associative study materials. Here is the play list for this course -
some presentation (and code samples) on Generators in Python? Generator Tricks for Systems Programmers
Python E-Books - e-Literature to get you started and free to boot
http://www.pythonxy.com/http://www.pycon.org/
PyTables is a package for managing hierarchical datasets and designed to efficiently and easily cope with extremely large amounts of data. You can download PyTables and use it for free. You can access documentation, some examples of use and presentations in the HowToUsesection.
--
http://atwork.wordpress.com (From Java to Python)
http://showmedo.com/learningpaths/12/view#start
http://gnosis.cx/publish/tech_index_cp.html
http://gnosis.cx/TPiP/ (text processing in Python)
-- note that there is also the "NLTK" -- Natural Language Processing (python) which is very good
https://www.enthought.com/
http://gnosis.cx/publish/tech_index_cp.html
http://gnosis.cx/TPiP/ (text processing in Python)
-- note that there is also the "NLTK" -- Natural Language Processing (python) which is very good
https://www.enthought.com/
comp.lang.python (google group)
Differences between Python 2 and 3 - This articles explains the subtle and not so subtle differences (print ('...'), input(...) and eval(input(..)) instead of raw_input and input in 3, etc)
Python Style Guide - Readability Counts! And hey this document shows a desire for standardization of coding to aid everyone in the community
PyDev - IDE
Generators Generators in Python:
Tricks, Tips, and Hacks:
Python Tips, Tricks, and Hacks
MIT OpenCourseWare
MIT 6.00 Intro to Computer Science & Program
Under MIT OpenCourseWare, all the lectures are available on MIT youtube channel with handouts and associative study materials. Here is the play list for this course -
some presentation (and code samples) on Generators in Python? Generator Tricks for Systems Programmers
Python E-Books - e-Literature to get you started and free to boot
- Dive Into Python – The original but not the best anymore. It taught me Python so I’ve got fond memories and a special place in my heart for it.
- How to Think Like a Computer Scientist: Learning With Python – A newly revised edition of this book is due out in Feburary 2009 but its still worth taking a look at the original.
- Text Processing in Python – I haven’t read it but I thoguht I’d add it for the sake of completeness.
- Start Programming With Python – Its a relatively new project started by an enthusiast. A hell of a lot has already been produced and its due to be finished by Xmas.
- PLEAC Python – Its like a rapid-fire Python Cookbook with short, concise examples of how to solve a variety of low-level problems. Form string manipulation to database access.
- Non-Programmers Tutorial for Python – Its for non-programmers but its sometimes useful to read form a different point of view. I find the perspective refreshing.
- Python 101 – Part of a university course this goes through the fundamentals as well as providing exercises.
- Thinking in Python Design Patterns and Problem-Solving Techniques – A mammoth title written by the great Bruce Eckel.
- Python Standard Library – This is seriously showing its age as it was originally written for Python 2.0. Although there’s updates they’re incomplete. Its still worth a look though to get a good idea of the Python core.
- Python Programming Tutorial – It looks okay, though nothing ground breaking.
- Django Book – A book on Pythons greatest web framework.
- Pylons Book – A book on Pythons 3rd best web framework.
- Sockets Programming in Python – I found this over at Scribd which is fast turning out to be a great little site. I recommend you look at some of the other books on offer once you’ve looked at this.
- Python Network Programming – Heavy on theory and light on practice. Still a worthy read when you need to sleep.
- Advanced Python Programming – This is actually a 126 slide lecture given by a Chicago University lecturer. Some good stuff in here.
“A Byte of Python”.
http://www.swaroopch.com/notes/Python
Python programming wiki book
http://en.wikipedia.org/wiki/Wikibooks:Python_Programming
Open-Source Book: Python 3 Patterns, Recipes and Idioms
http://www.mindviewinc.com/Books/Python3Patterns/Index.php
http://www.pythonxy.com/
Python Links
Core
- www.python.org
- The Python Tutorial
- Python 2.5 reference card
- Python Quick Reference ( 2.5 , 2.4)
- Building Skills in Python
- How to Think Like a (Python) Programmer
- Dive Into Python
- A Byte of Python
- Python-by-example
- Useful simple examples from the Python Standard Library
- String documentation
- Google's Python Class
- MIT Introduction to Computer Science and Programming
General Scientific Programming
- (Very) Simple (Numerical) Recipes in Python
- scipy (docs).
- numpy ( Numpy reference, Simple Examples)
- Summary of NumPy Commands
- Arrays in SciPy/Numpy/Python (attributes, methods, functions)
- SciPy Course
- Minuit numerical function minimization in Python
- PyMC Markov chain Monte Carlo package
- Python Scripting for Computational Science
- Numerical Methods in Engineering with Python (2nd Edition) by Jaan Kiusalaas ( Examples )
- Physical constants in python
- Python Imaging Library (PIL)
- RPy - R from Python
Calling c functions and fortran subroutines
Plotting
Pgplot and ppgplot
- pgplot
- Subroutine Descriptions
- pgplot colours, symbols, line types
- ppgplot ( local copy of ppgplot-1.3.tar.gz ).
- pgplot, ppgplot and gfortran
- Using ppgplot on Durham ITS, first star.init, then try the demo programmes
jor_comp.py, (data file)
ex_graph.py
ex_arro.py
ex_panel.py
ex_cont.py
ex_sierp.py
Astronomy
- pyfits
- Topical Software
- Astronomy Tutorial (pdf)
- pyraf
- PyEphem
- VOTable.py
- Python version of Ned Wright's Cosmology Calculator by James Schombert.
- Scott Ransom's pySLALIB python+numpy wrappers for the SLALIB
- Russell Owen's RO Python Package
- Russell Owen's AstroPy Links
- Matt Hilton's astLib (Python tools for Astronomy)
Example Python Programs and Functions
- Find the median of an array (source)
- Angular separation of two points on the Celestial Sphere (source)
- Bearing (position angle) of one point on a sphere relative to another (source)
- To the azimuth and elevation of celestial object (source)
- Convert from J2000 equatorial coordinates to galactic coordinates (source)
- To find aperture magitudes for a set of x, y position on an image (source)
- Incomplete Gamma functions, etc (gammln, gser, gcf, gammp, gammq translated from Numerical Recipes) (source)
- plot_prof.py Plots galaxy surface brightness curves, outputs: prof.ps
- plot_petro.py Plots petrosian functions for a range of sersic profiles, outputs: petro.ps
- make_galfit_gal.py Create bulge and disk images from GALFIT output fit.log file
- Average a set of JPEGS with PIL and numpy (source)
- Convert the SDSS photo flag hex number into the flag names (source, PhotoFlags.dat)
- Make up 2d gaussian fits image (source).
- Example of using scipy.signal.convolve2d (source). Input fits files (gal.fits, psf.fits).
- How to use the signal timeout (source).
- Using astLibs to make up a postage stamp image (source)
- Examples of file locking in GCC and python
PyTables is a package for managing hierarchical datasets and designed to efficiently and easily cope with extremely large amounts of data. You can download PyTables and use it for free. You can access documentation, some examples of use and presentations in the HowToUsesection.
--
♥ ¸¸.•*¨*•♫♪♪♫•*¨*•.¸¸♥
Subscribe to:
Comments (Atom)